736
据报道,国外研究小组基于MonoScene开发出VoxFormer,对摄像头的SSC解决方案进行进一步的研究。其中MonoScene使用密集特征投影将2D图片输入转换为3D。然而,这样的投影给出了可视区域中空的或遮挡的体素2D特征。例如,被汽车覆盖的空体素仍然会获得汽车的视觉特征。因此,创建的3D特征在几何完整性和语义分割方面表现不佳。与MonoScene相比,VoxFormer将3D到2D交叉注意力视为稀疏查询的表示,且主要受到两个认识的启发:(1)3-D空间中的稀疏性:由于3-D空间的很大一部分通常是空的,因此稀疏表示(而不是密集表示)无疑更有效和可扩展。(2)幻觉前重建(reconstruction-before-hallucination):以重建的可见区域为起点,可以更好地完成不可见区域的3D信息。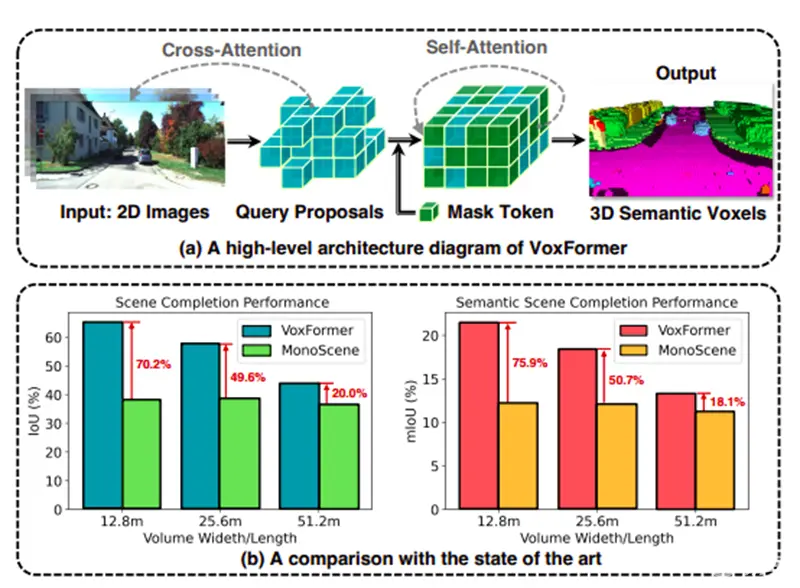
标签:
内容由作者提供,不代表易车立场






